

基础算法
基础算法-1 对比自监督学习的泛化(ICLR 23)
针对各类对比学习算法,提出了一个统一的理论框架来分析,并由此推导出自监督对比学习在下游任务的泛化误差上界。根据该误差上界,得出泛化性好的三个条件:正样本对齐、类中心错开、增广后的数据分布聚焦。首次从理论上解释了自监督对比学习泛化性好的原理。
.png)
.png)
不同数据增强组合性能变化趋势的预测曲线和实测曲线 图灵奖得主LeCun等人关于自监督的综述中,在理论章节的开篇首先引用了我们的工作
基础算法-2 基于对比学习的持续学习(ICML 24)
之前的研究发现,在持续学习中采用对比损失和蒸馏损失的组合进行训练能够取得良好的性能表现。然而,这种对比持续学习框架缺乏足够的理论解释。我们从理论层面对基于对比学习损失的持续学习方法加以分析,建立了理论保证来填补理论上的一些空白,首次严格给出了对比学习模型在持续学习时的性能上限和下限,并且基于理论分析启发提出了全新的持续学习算法。
.jpg)
基础算法-3 基于快和慢思考的持续学习(NeurIPS 24)
在数据流中持续学习新概念并防止遗忘,是人工智能领域的关键挑战。尽管强大的预训练模型已成为主流,但现有方法通常仅将其作为参数起点,通过微调适应初始任务,随后便冻结参数以防遗忘。这种策略不仅未能充分利用预训练模型的泛化知识,也限制了模型学习后续新概念的能力。为解决这些局限,我们提出了一个名为 SAFE 的全新框架,它基于快慢学习理论,旨在更有效地进行增量学习。
.jpg)
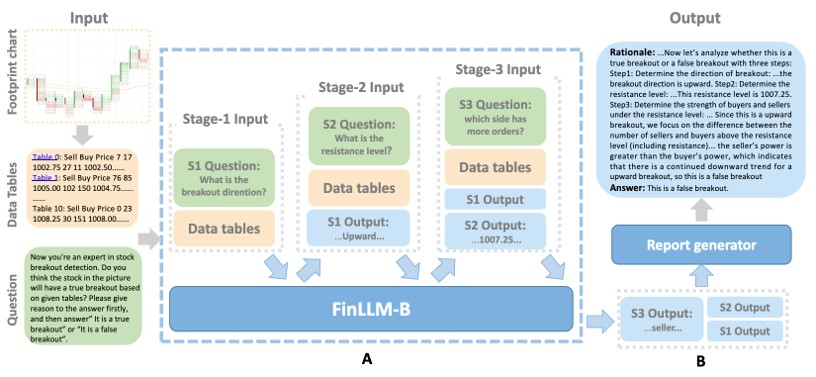
基础算法-4 金融交易突破检测大模型(NAACL 25)
针对金融交易中的突破检测问题,为了实现区分真假突破并提供正确理由,提出了一个FinLLM-B 大模型,该模型采用了一种新颖的多阶段结构 ,实现了对突破交易策略有效性的提升 ,与GPT-3.5相比,答案和理由的平均准确率提高了49.97%,并且优于ChatGPT-4的42.38% 。.
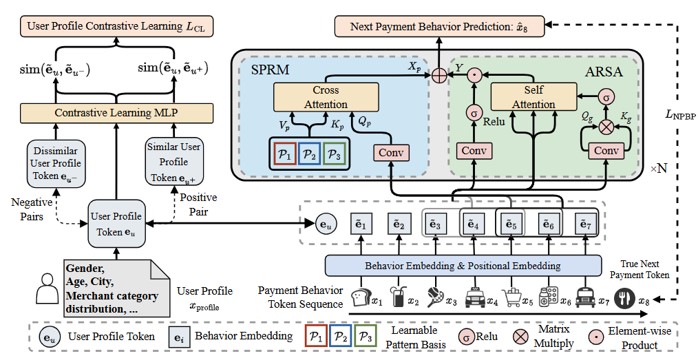
基础算法-5 微信支付行为预测大模型
针对微信支付数据的高基数、低延迟以及数据标注有限等挑战 ,提出了一种名为 PANTHER 的混合框架,该框架结合了自监督生成式预训练和轻量级判别模型 ,在微信支付的欺诈检测任务上将高风险区间的召回率相对提升了 38.6% ,性能显著优于 Transformer 等基线模型 ,并在下游推荐任务(如 Yelp 数据集)上,相较于 DCN 基线模型在 NDCG@5 指标上取得了 29.6% 的提升 。
版权所有 上海交通大学空天智能光电技术实验室